仮説なしの多変量解析によるNMRメタボロームデータの要約
NM170013
はじめに
近年、NMRによって代謝産物の総体(メタボローム)を混合物のまま解析するNMR代謝プロファイリング (NMR metabolic profiling; NMR-MP) がポストゲノム研究や品質管理などで盛んに用いられています。NMR-MPは、ノンターゲットメタボロミクスの一手法です。ノンターゲットの解析では、解析の対象が広範にわたるため、NMRスペクトルから直接データを解釈するのは困難です。多変量解析を適用することで、多変量データから有用な知見を発掘できます(データマイニング)。
データマイニングでは、実験系および目的に合わせてデータの要約、分類、モデリング、回帰(予測)などの適切な多変量解析を適用することが重要です。ここでは、仮説なし∗(試料の群情報や外部変数を使わない)でデータを要約する手法である"主成分分析"と"階層的クラスター解析"をNMRメタボロームデータに適用した例を紹介します。
試料と方法
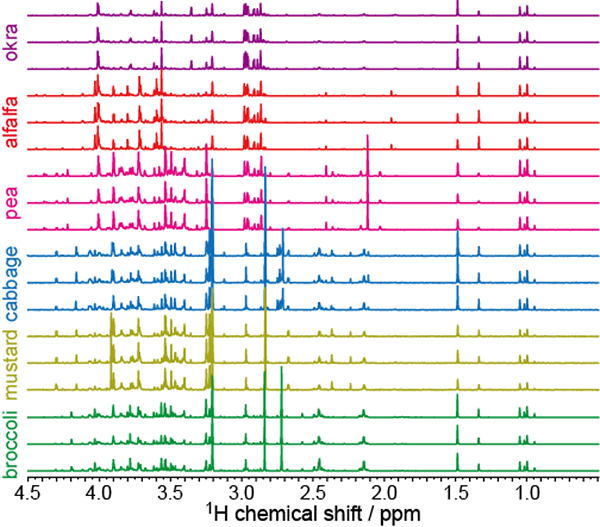
6種類の市販の野菜のスプラウト(ダイコン、ブロッコリ、マスタード、アルファルファ、エンドウ、オクラ)から、Bligh-Dyer法に準ずる方法で代謝産物を抽出し、極性画分を遠心エバポレータで乾固しました。乾固した極性代謝産物を、重水で調製したpH = 7.0の100 mM リン酸カリウム緩衝液で再溶解させ、NMR試料としました。1H-NMR計測には、2次元J分解分光法を用いました。J分解スペクトルのf2プロジェクションからは、JHHによる分裂のない(Jカップリングの消去された)化学シフトのみのスペクトルが得られるため [1]、スペクトルを単純化させることができます (Figure 1)。それぞれのスプラウトにつき3試料を調製しました。
それぞれのスペクトルの0.5-9.0 ppmの範囲を、等幅の積分範囲(0.02 ppm幅)で積分しました(バケット積分)。ここでノイズレベルの変数は、多変量解析に供する前に削除しました。結果として101変数∗18試料からなる行列(多変量データ)が得られました。主成分分析および階層的クラスター分析は、R言語の統計解析関数(無料)を用いて計算しました。
主成分分析の適用
主成分分析では、与えられた多変量から分散(≒情報量)が最大となるように各変数の線形結合として主成分を作成します。その結果、多次元のデータ(多変量)をより少ない次元で説明できるようになります。式1の線形結合式から主成分分析におけるスコアと因子負荷量の関係を示します。通常、中央化(各変数から平均値を差し引く処理)と、必要に応じてスケーリングをおこないます。

式1から、スコアと因子負荷量の対応から試料間の特徴を解釈できます。iは試料番号を、jは変数番号または主成分数を表します。ここでは、固有ベクトルを因子負荷量としています。
主成分分析の結果をFigure 2に示します。アブラナ科のスプラウトであるダイコン、ブロッコリ、マスタードの第一主成分 (PC1) のスコアは負であり、それ以外のアルファルファ、エンドウ(マメ科)、オクラのスコアは正でした (Figure 2 (a))。負荷因子量では、アスパラギンなどがPC1の正に、グルタミンなどが負に寄与していることがわかります (Figure 2(b))。
スプラウトなどの若い植物では、アスパラギンやグルタミンなどの側鎖にアミノ基を有するアミノ酸が窒素代謝において重要な役割を担うことが知られています [2]。これらの組成は、植物の種や環境によって異なります。例えばアブラナ科の植物ではグルタミンが、マメ科の植物ではアスパラギンが側鎖にアミノ基を有するアミノ酸では主要であることが報告されています [3]。また、光合成ができない環境では、よりC/N比の小さいアスパラギンを選択的に合成することが知られています [4]。
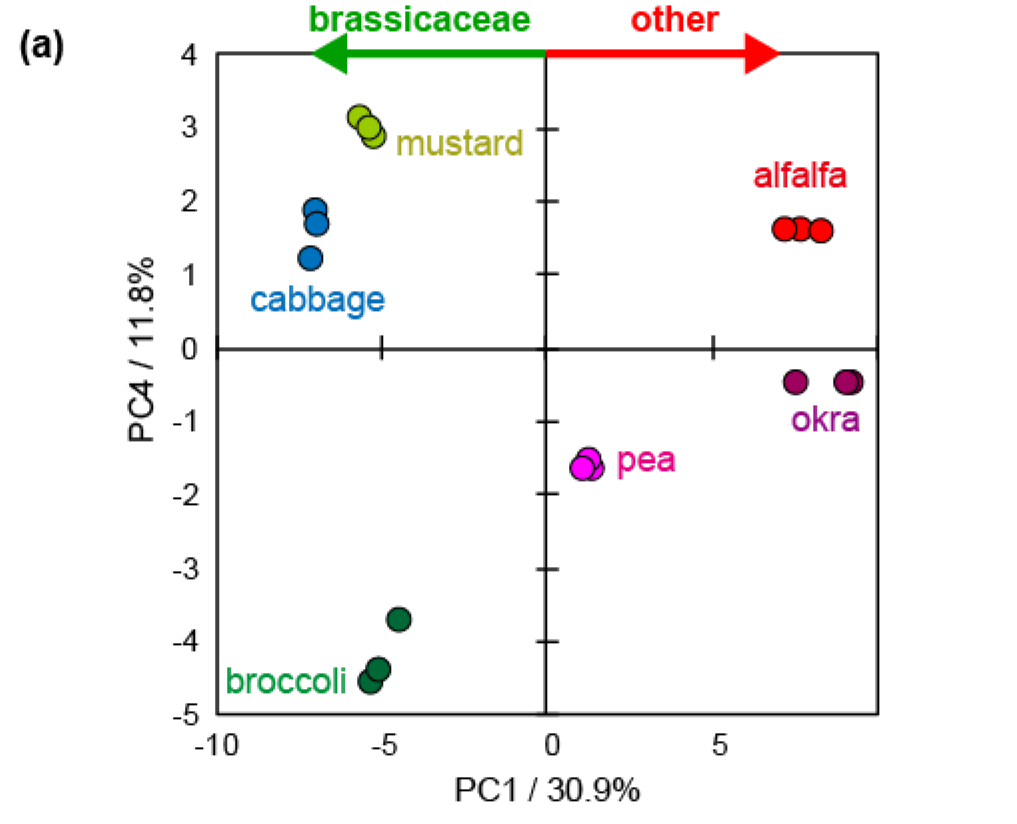
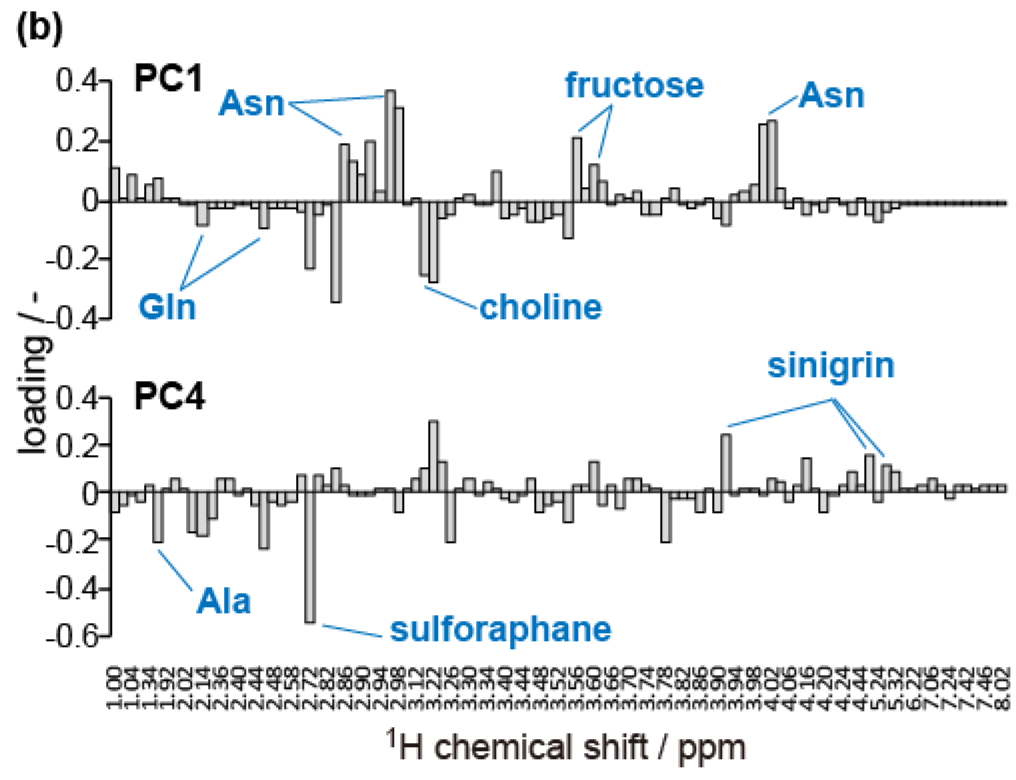
Figure 2. スプラウト抽出極性代謝産物1H-NMRスペクトルの主成分分析。(a) スコアプロット、(b) PC1およびPC4の因子負荷量。スペクトルの総和でノーマライズし、中央化したデータから主成分分析をおこなった。
階層的クラスター分析の適用
階層的クラスター分析は、各試料あるいは変数間の距離を定義し、距離が近いものを逐次的にクラスターとして連結することで、データ間の関係性をデンドログラム(樹形図)として要約する手法です。ヒートマップと併用することで、試料と代謝産物の関係性の解釈が容易になります。データ間の距離の定義として、ユークリッド距離(式2)が一般的ですが、ここでは、ピアソンの積率相関系数に基づいた相関距離(式3)を用いました。
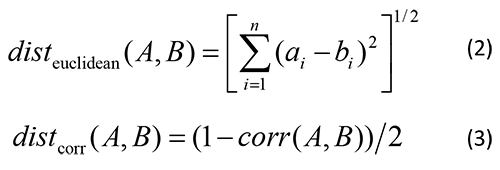
ここでaiおよびbiは、それぞれAおよびBのi番目の変量、corr(A,B)はピアソンの積率相関係数を表します。
階層的クラスター分析から得られたヒートマップをFigure 3に示します。ヒートマップの行および列方向は、それぞれ変数と試料に対応します。左および上部に示すデンドログラムは、それぞれ変数間および試料間の相関距離を階層構造で示しています。試料間のデンドログラムでは、主成分分析同様にアブラナ科のスプラウトとそれ以外が分かれました。変数間のデンドログラムでは、同じ分子に由来する信号および異なる分子だが相関が高い信号がクラスタリングされています。緑~赤のグラデーションで示されたヒートマップは、デンドログラムに従って並べ替えされており、各試料および試料群に特異的に存在する代謝産物が可視化されています。例えば、イソチオシアネートのスルフォラファンがブロッコリに多く含まれており、グルコシノレートの一種であるシニグリンがマスタードに多く含まれていることがわかります[5]。
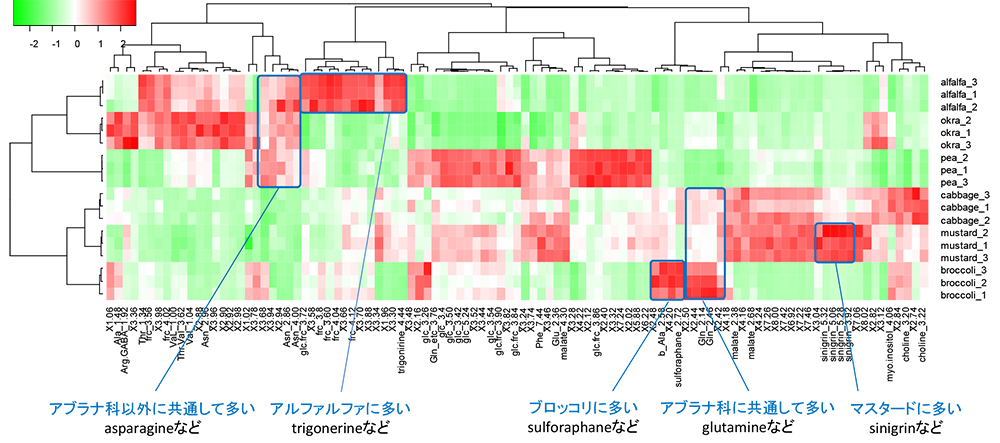
Figure 3. スプラウト抽出極性代謝産物の1H-NMRスペクトルに基づくヒートマップおよび階層的クラスター分析。行および列は変数および試料に対応する。変数間および試料間では相関距離を用い完全連結法でクラスターを形成した。ヒートマップには、オートスケーリングされたデータを用いた。よって試料間で相対的に存在量が多い代謝産物と少ない代謝産物が赤と緑の濃淡で示される。ヒートマップからは、各試料に特有な代謝産物の情報が視覚的に得られる。glc: glucose、frc: fructose、アミノ酸は三文字略号で記す。
NMR-MPの特徴として、多くの質量分析法とは異なりクロマトグラフィなどによる分離操作をおこなわない点、再現性が非常に高い点が挙げられます。質量分析法によるメタボローム解析の多くは、対象とする分子種に合わせて固相、移動相、イオン化法、代謝産物抽出法の選択などの検討が重要です。一方、NMRでは分離操作がなく、溶液に溶けたほぼすべての分子が検出対象になるため、実験系の検討の時間と手間を省くことができます。また、分析試料のキャリーオーバーの心配もありません。選択性や感度が求められる詳細な代謝の解析には、質量分析法が第一選択肢となります。仮説などがない状態から、データを計測して、教師なしの多変量解析を "とりあえず" おこなうfirst (or fast) screeningとしてNMR-MPは効果的です。
∗ 仮説なしの多変量解析を教師なし多変量解析とよびます。一方、仮説(試料の群情報や外部変数)を利用する多変量解析を教師あり多変量解析とよびます。
参考文献
- 弊社アプリケーションノート "NMR代謝プロファイリングなどにおける混合物の1Hスペクトルの単純化"(NM170014)
- Komatsu; T. et al., Metabolites (2014) 4, 1018.
- Nord; F. F. and Street; H. E., "Nitrogen Metabolism of Higher Plants" in Advances in Enzymology (1949) 9, John Wiley & Sons, Inc, 391.
- McGrath; R.B. et al., Plant J. (1991) 1, 275.
- Rangkadilok; N. et al., Sci. Hort. (2002) 96, 11.
- このページの印刷用PDFはこちら。
クリックすると別ウィンドウが開きます。 
PDF 1.23MB